Chapter 10 Regression
10.1 Review
So far, we’ve made comparison between sets of measurements by…
- Comparing the histograms of the sets of measurements (e.g., the ideologies of representatives from the 100th and 115th Congresses).
- Comparing the average or SD of sets of the measurements (e.g., the ideologies of representatives from the 100th and 115th Congresses).
- Computing the correlation coefficient between two sets of measurements (e.g., the portfolio share and the seat share for coalition governments)
Regression allows us to extend the correlation coefficient–a measure of how well two variables “go together”–into a more intuitive, informative quantity.
Regression allows us to answer the question “What is the average of \(y\)?” for many different values of \(x\). Rather than compare a small number of scenarios (e.g., the 100th and 115th Congresses), the regression line allows us to compare the average of \(y\) as \(x\) varies continuously.
In short, we describe the average value of \(y\) as a linear function of \(x\), so that
\(\text{the average of } Y = mX + b\).
Before we hop into regression, let’s review where we’ve been. Let’s do it with an exercise.
Exercise 10.1 One of the simplest democratic mechanims goes like this: If things are going well, vote for the incumbent. If things are going poorly, vote against the incumbent. Normatively, we want to see voters punish incumbents for bad outcomes.
Let’s see if incumbents get fewer votes when things go poorly. The dataset below shows incumbent presidents’ margins of victory (in the popular vote) and the percent change in the real disposable income from Q2 in the year before the election to Q2 in the year of the election.
Do the following analyses with “pencil-and-paper.” Feel free to use R or Excel to assist with this exercise–I just don’t want you using the sd() function for example–I just want you computing things manually as a final reminder for how things work.
- Use the percent change in the RDI to break incumbents into “good performers” and “bad performers”. You may use more than two categories if you want. Draw a histogram of the margin of victory for the good performers and another for the bad performers. Compare and interpret.
- Compute the average and SD for each category. Compare and interpret.
- Compute the correlation between the percent change in the RDI and the margin of victory. Interpret.
Now replicate the pencil-and-paper work with R. You can find the data here.
Overall, do voters punish incumbents for bad outcomes?| Year | Incumbent | % Change in RDI | Margin of Victory |
|---|---|---|---|
| 2016 | H. Clinton | 0.89 | 2.23 |
| 2012 | Obama | 2.83 | 3.93 |
| 2008 | McCain | 1.30 | -7.38 |
| 2004 | GWB | 2.67 | 2.49 |
| 2000 | Gore | 4.13 | 0.54 |
| 1996 | B. Clinton | 2.21 | 9.47 |
| 1992 | GHWB | 2.93 | -6.91 |
| 1988 | GHWB | 4.80 | 7.80 |
| 1984 | Reagan | 6.66 | 18.34 |
| 1980 | Carter | -1.08 | -10.61 |
| 1976 | Ford | 0.10 | -2.10 |
| 1972 | Nixon | 2.10 | 23.57 |
| 1968 | Humphrey | 4.04 | -0.81 |
| 1964 | Johnson | 6.09 | 22.69 |
| 1960 | Nixon | 0.31 | -0.17 |
| 1956 | Ike | 3.23 | 15.50 |
| 1952 | Stevenson | 0.44 | -10.90 |
| 1948 | Truman | 4.49 | 4.74 |
Two warnings:
- Social scientists use the term “regression” imprecisely. In one case, they might use “regression” to refer to a broad class of models. In another case, they might use it to refer to the particular model discussed below. So watch out for inconsistent meanings, but the context should make the meaning clear.
- Methodologists often motivate regression from a random sampling perspective. This is not necessary but it’s common. In my view, it’s unfortunate because regression is a useful tool with datasets that are not random samples and it unnecessarily complicated the results. However, in the random sampling framework, one can motivate the methods below quite elegantly.
10.2 The Equation
Let’s start by describing a scatterplot using a line. Indeed, we can think of the regression equation as an equation for a scatterplot.
First, let’s agree that we won’t encounter a scatterplot where all the points \((x_i, y_i)\) fall exactly along a line. As such, we need a notation that allows us to distinguish the line from the observed values.
We commonly refer to the values along the line as the “fitted values” (or “predicted values” or “predictions” and the observations themselves as the “observed values” or “observations.”
We use \(y_i\) to denote the \(i\)th observation of \(y\) and use \(\hat{y}_i\) to denote the fitted value (usually given \(x_i\)).
We write the equation for the line as \(\hat{y} = \alpha + \beta x\) and the fitted values as \(\hat{y}_i = \alpha + \beta x_i\).
We refer to the intercept \(\alpha\) and the slope \(\beta\) as coefficients.
We refer to the difference between the observed value \(y_i\) and the fitted value \(\hat{y}_i = \alpha + \beta x_i\) as the residual \(r_i = y_i - \hat{y}_i\).
Thus, for any \(\alpha\) and \(\beta\), we can write \(y_i = \alpha + \beta x_i + r_i\) for the observations \(i = \{1, 2, ..., n\}\).
Notice that we can break each \(y_i\) into two pieces components
- the linear function of \(x_i\): \(\alpha + \beta x_i\)
- the residual \(r_i\).
In short, we can describe any scatterplot using the model \(y_i = \alpha + \beta x_i + r_i\).
- The black points show the individual observations \((x_i, y_i)\),
- The green line shows the equation \(\hat{y} = \alpha + \beta x\).
- The purple star shows the prediction \(\hat{y}_i\) for \(x = x_i\).
- The orange vertical line shows the residual \(r_i = y_i - \hat{y}_i\).
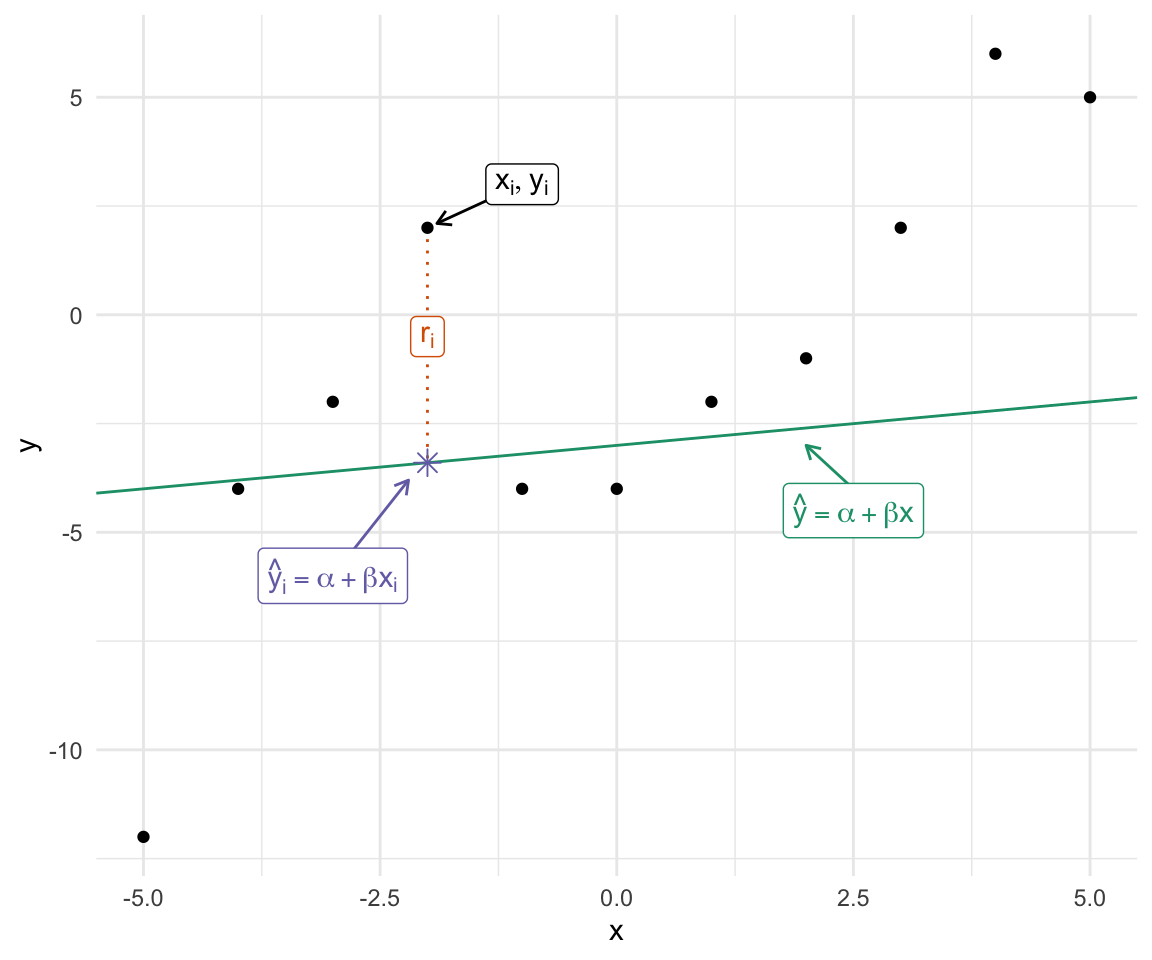
Using this generic approach, we can describe any scatterplot using any line. Of course, the line above isn’t a very good line.
How can we go about finding a good line?
Hint
- Realize that the \(\theta\) that minimizes \(f(\theta) = \sqrt{\dfrac{\displaystyle \sum_{i = 1}^n (y_i - \theta)^2}{n}}\) also minimizes \(g(\theta) = \dfrac{\displaystyle \sum_{i = 1}^n(y_i - \theta)^2}{n}\). We know this because the square root function is monotonically increase (for positive values, which this must always be) and preserves the order of observations. In other words, the \(\theta\) that produces the smallest RMS of the deviations also produces the smallest MS of the deviations.
- Realize that the \(\theta\) that minimizes \(g(\theta) = \dfrac{\displaystyle \sum_{i = 1}^n(y_i - \theta)^2}{n}\) also minimizes \(h(\theta) = \displaystyle \sum_{i = 1}^n(y_i - \theta)^2\). Removing a constant just shifts the curve up or down, but it does not change the \(\theta\) that minimizes the curve. So work with \(h(\theta) = \displaystyle \sum_{i = 1}^n(y_i - \theta)^2\).
- To make things easier, expand \(h(\theta) = \displaystyle \sum_{i = 1}^n(y_i - \theta)^2\) to \(h(\theta) = \displaystyle \sum_{i = 1}^n(y_i^2 - 2\theta y_i + \theta^2)\).
- Distribute the summation operator to obtain \(h(\theta) = \displaystyle \sum_{i = 1}^n y_i^2 - 2 \theta \sum_{i = 1} y_i + n\theta^2\).
- Now take the derivative of \(h(\theta)\) w.r.t. \(\theta\), set that derivative equal to zero, and solve for \(\theta\). The result should be familiar.
Exercise 10.3 See how other authors conceptualize the regression model.
- Read Lewis-Beck (1980), pp. 9-13 (up to “Least Squares Principle”)
- Read Wooldridge (2013), pp. 22-26 (Section 2.1). Do q. 1, p. 60.
10.3 The Conditional Average
Have a look at the scatterplot below. What’s the portfolio share of a party in a coalition government with a seat share of 25%?
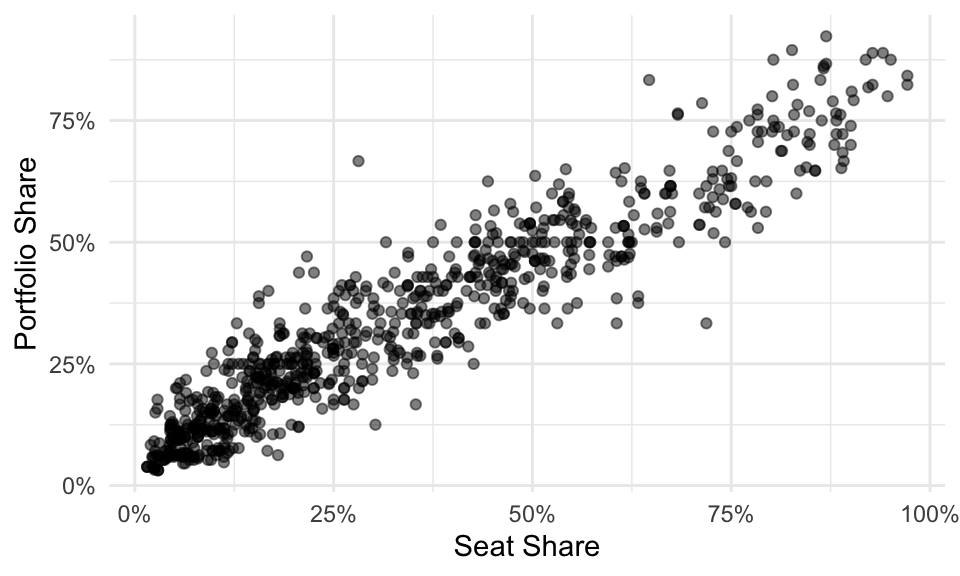
Your eyes probably immediately begin examining a vertical strip above 25%.
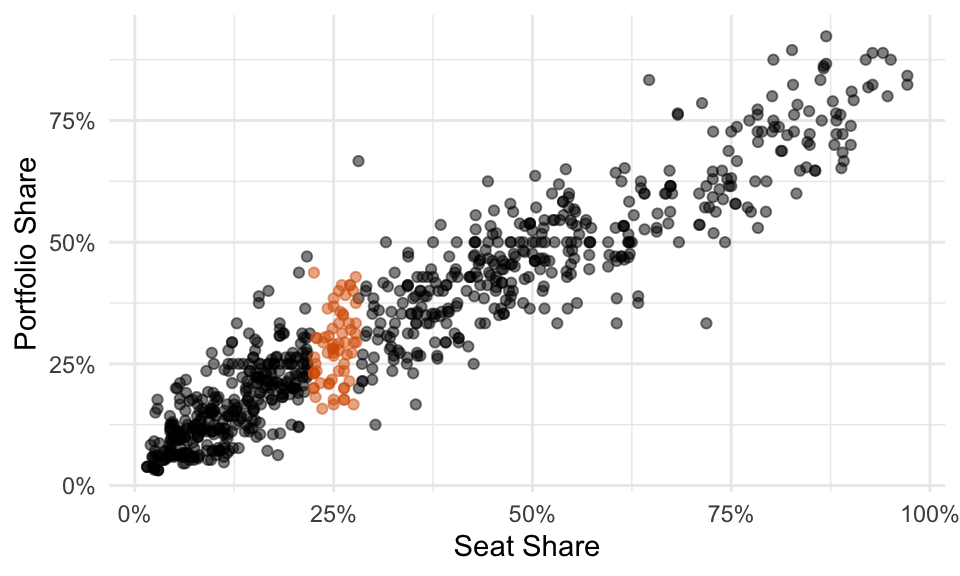
You probably estimate the average is a little more than 25%… call it 27%. You can see that the SD is about 10% because you’d need to go out about 10 percentage points above and below the average to grab about 2/3rds of the data.
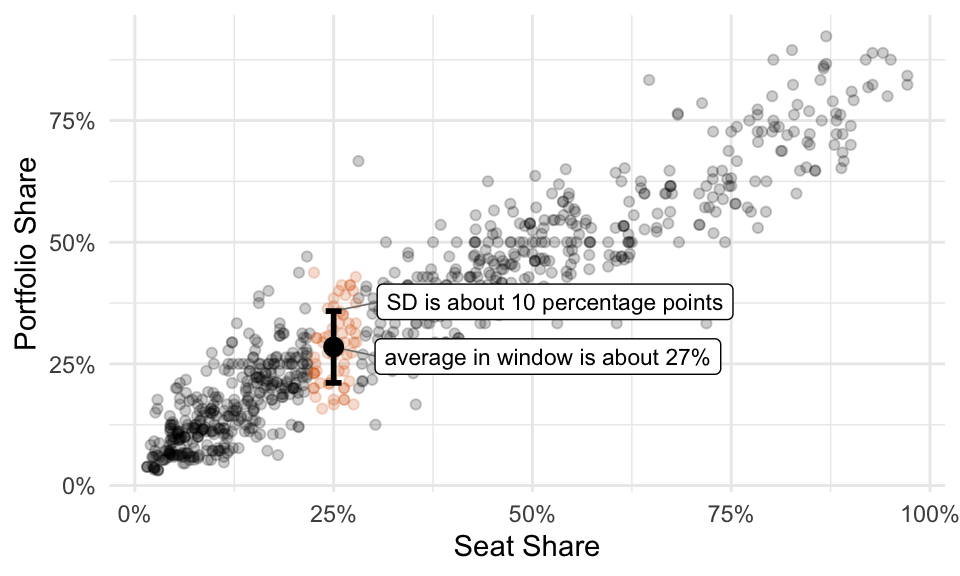
Now you’re informed by the data and ready to answer the question.
- Q: What’s the portfolio share of a party in a coalition government with a seat share of 25%?
- A: It’s about 28% give or take 10 percentage points or so.
Notice that if we break the data into many small windows, we can visually create an average (and an SD) for each. Freedman, Pisani, and Purves (2008) refer to this as a “graph of averages.” Fox (2008) calls this “naive nonparametric regression.” It’s a conceptual tool to help us understand regression.
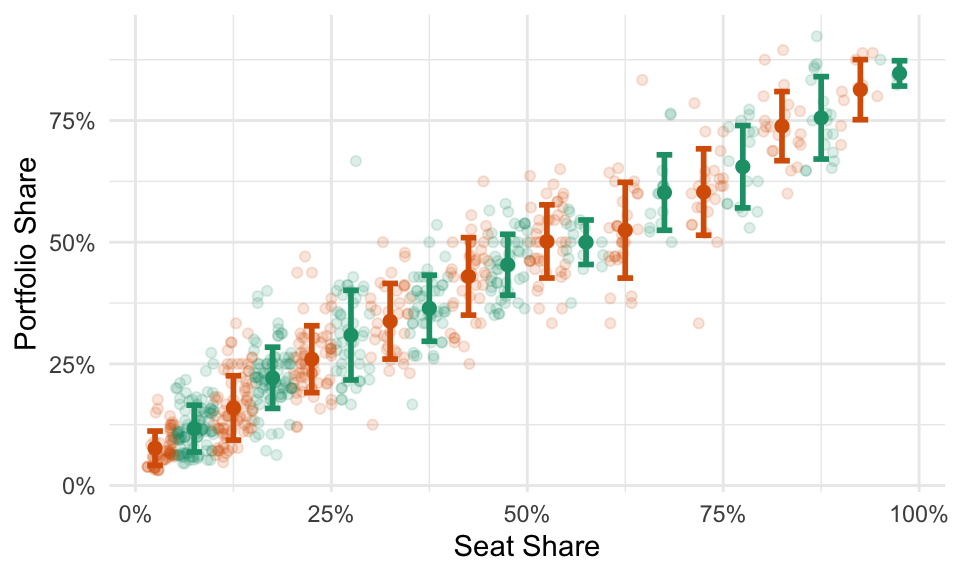
For some datasets, these averages will fall roughly along a line. In that case, we can described the average value of \(y\) for each value of \(x\)–that is, the conditional average of \(y\)–with a line.
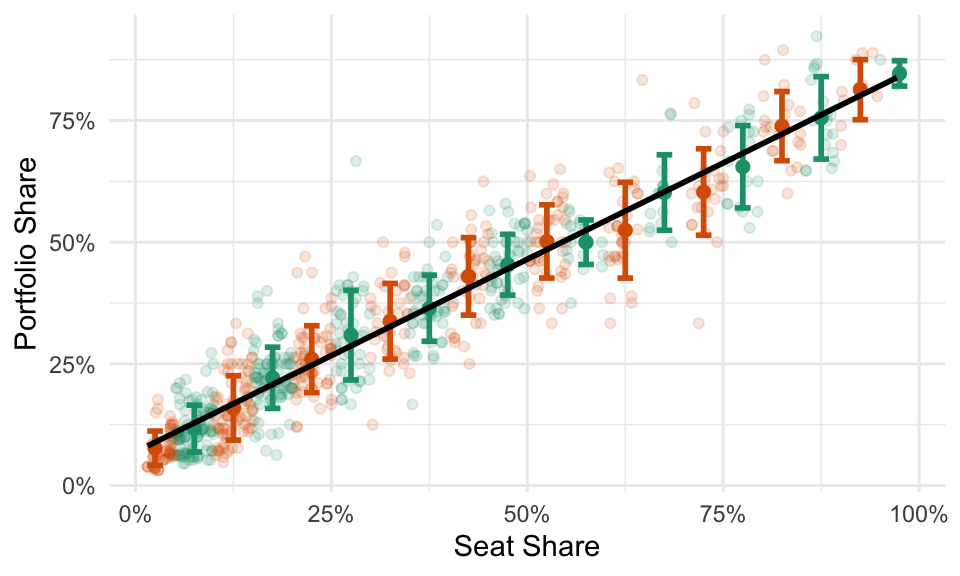
Here’s the takeaway: a “good” line is the conditional average.
Exercise 10.4 Other authors use this “graph of averages”.
- Read FPP, ch. 10.
- Set A, p. 161: 1-4.
- Set B, p. 163: 1, 3.
- Set C, p. 167: 1-3.
- Set D, p. 174: 1, 2.
- Set E, p. 175: 1, 2.
- Section 6, p. 176: 1-3, 5-7, 10.
- Read Read Fox (2008), pp. 17-21. (Optional: Section 2.3 describes how to create a smoothed average in a more principled manner.)
10.4 The Best Line
So far, we have to results:
- The average is the point that minimizes the RMS of the deviations.
- We want a line that captures the conditional average.
Just as the average minimizes the RMS of the deviations, perhaps we should choose the line that minimizes the RMS of the residuals… that’s exactly what we do.
We want the pair of coefficients \((\hat{\alpha}, \hat{\beta})\) that minimizes the RMS of the residuals or
\(\DeclareMathOperator*{\argmin}{arg\,min}\)
\[\begin{equation} (\hat{\alpha}, \hat{\beta}) = \displaystyle \argmin_{( \alpha, \, \beta ) \, \in \, \mathbb{R}^2} \sqrt{\frac{r_i^2}{n}} \end{equation}\]
Let’s explore three methods to find the coefficients that minimize the RMS of the residuals.
- grid search
- numerical optimization, to get additional intuition and preview more advanced methods
- analytical optimization
10.4.1 Grid Search
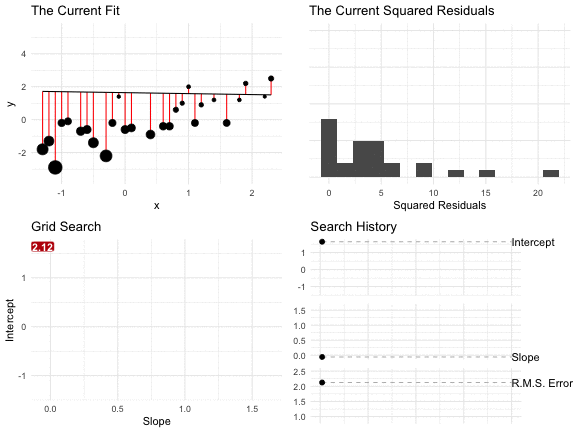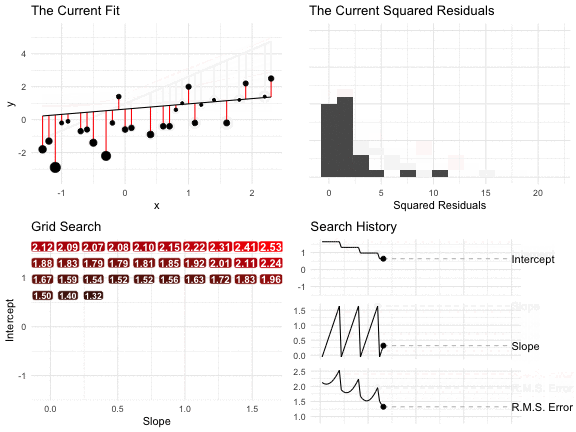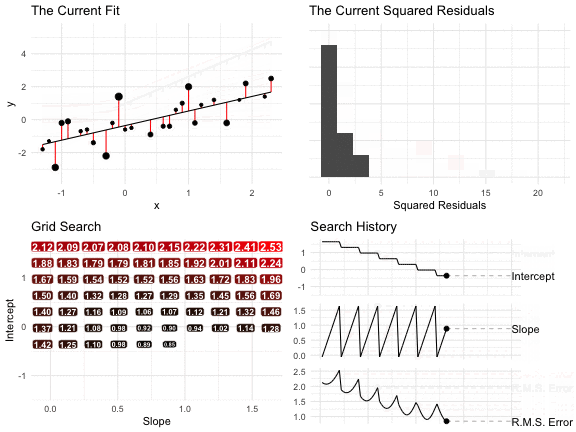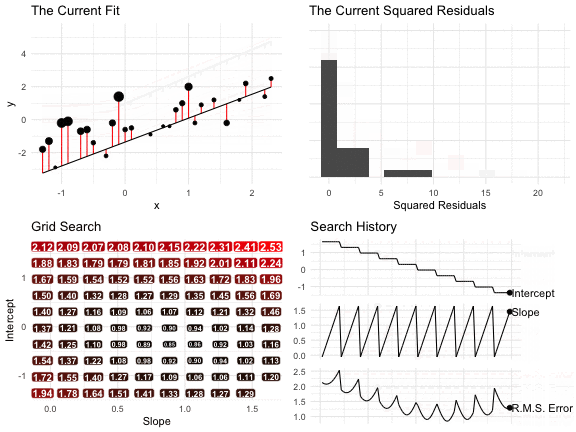
Because we’re looking for the pair \((\hat{\alpha}, \hat{\beta})\) that minimize the sum of the RMS residuals, we could simply check lots of different values. In some applications, this is a reasonable optimization routine. (It is not reasonable in the context of regression, where we have much faster and accuracy tools.)
The figure below shows the result of a grid search.
- In the top-left panel, we see the line and the residuals for each intercept-slope pair. The size of the points indicates the residual squared. Notice that some lines make big errors and other lines make small errors.
- In the top-right panel, we see a histogram of the squared residuals.
- In the lower-left panel, each point in the grid shows a intercept-slope pair. The label, color, and size indicate the RMS of the residuals. As we move around the grid, the RMS changes–we’re looking for the smallest.
- In the lower-right panel, the three lines show the evolution of the intercept, slope, and RMS of the residuals, respectively. Again, we’re looking for the pair that produces the smallest RMS of the residuals.
For this search, the intercept -0.36 and the slope 0.89 produce the smallest RMS of the residuals (of the combinations we considered).
10.4.2 Numerical Optimization
Remember that we simply need to minimize the function
\(f(\alpha, \beta) = \displaystyle \sqrt{\frac{\sum_{i = 1}^n r_i^2}{n}} = \sqrt{\frac{\sum_{i = 1}^n (y_i - \hat{y}_i)^2}{n}} = \sqrt{\frac{ \sum_{i = 1}^n [y_i - (\alpha + \beta x_i)]^2}{n}}\),
shown below.
Hill-climbing algorithms, such as Newton-Raphson, find the optimum numerically by investigating the shape of \(f\) at its current location, taking a step uphill, and then repeating. When no step leads uphill, the algorithm has found the optimum. Under meaningful restrictions (e.g., no local optima), these algorithms find the global optimum.
First, let’s add the data from the grid search example above using tribble().
df <- tribble(
~x, ~y,
-1, -0.2,
1.1, -0.2,
-1.1, -2.9,
-0.2, -0.2,
-0.5, -1.4,
1.9, 2.2,
1.2, 0.9,
0.1, -0.5,
0.7, -0.4,
-1.3, -1.8,
2.3, 2.5,
0.4, -0.9,
1, 2,
-0.9, -0.1,
-0.1, 1.4,
-1.2, -1.3,
0.9, 1,
0, -0.6,
-0.6, -0.6,
-0.3, -2.2,
1.4, 1.2,
1.8, 1.2,
1.6, -0.2,
2.2, 1.4,
-0.7, -0.7,
0.6, -0.4,
0.8, 0.6
)Now let’s create a function that takes the parameters (to be optimized over) as the first argument.
f <- function(par, data) {
alpha <- par[1]
beta <- par[2]
y_hat <- alpha + beta*data$x
r <- data$y - y_hat
rms <- sqrt(mean(r^2))
return(rms)
}Now we can optimize this function f() using optim(). The default method is "Nelder-Mead", which works similarly to the Newton-Raphson algorithm you might have seen before.
results <- optim(
par = c(0, 0), # initial slope and intercept
fn = f, # function to optimize
data = df # dataset for f()
)
results$par[1] -0.3595557 0.9414289[1] 0.8448945The Nelder-Mead optimization routine finds that intercept of -0.36 and a slope of 0.94 result in the smallest RMS of the residuals 0.84.
This somewhat agrees with the results from the coarse grid search. If the grid search were more fine-grained, we could easily obtain solutions that agree to two decimal places.
10.4.3 Analytical Optimization
In the case of finding the line that minimizes the RMS of the residuals, we have an easy analytical solution. We don’t need a grid search, and we don’t need to optimize numerically.
10.4.3.1 Scalar Form
Remember that we simply need to minimize the function
\(f(\alpha, \beta) = \displaystyle \sqrt{\frac{\sum_{i = 1}^n [y_i - (\alpha + \beta x_i)]^2}{n}}\).
This is equivalent to minimizing \(h(\alpha, \beta) = \sum_{i = 1}^n(y_i - \alpha - \beta x_i)^2\). We sometimes refer to this quantity as the SSR or “sum of squared residuals.”
To minimize \(h(\alpha, \beta)\), remember that we need to solve for \(\frac{\partial h}{\partial \alpha} = 0\) and \(\frac{\partial h}{\partial \beta} = 0\) (i.e., the first-order conditions).
Using the chain rule, we have the partial derivatives
\(\frac{\partial h}{\partial \alpha} = \sum_{i = 1}^n [2 \times (y_i - \alpha - \beta x_i) \times (-1)] = -2 \sum_{i = 1}^n(y_i - \alpha + \beta x_i)\)
and
\(\frac{\partial h}{\partial \beta} = \sum_{i = 1}^n 2 \times (y_i - \alpha - \beta x_i) \times (-x_i) = -2 \sum_{i = 1}^n(y_i - \alpha - \beta x_i)x_i\)
and the two first-order conditions
\(-2 \sum_{i = 1}^n(y_i - \hat{\alpha} + \hat{\beta} x_i) = 0\)
and
\(-2 \sum_{i = 1}^n(y_i - \hat{\alpha} + \hat{\beta} x_i)x_i = 0\)
10.4.3.1.1 The 1st First-Order Condition
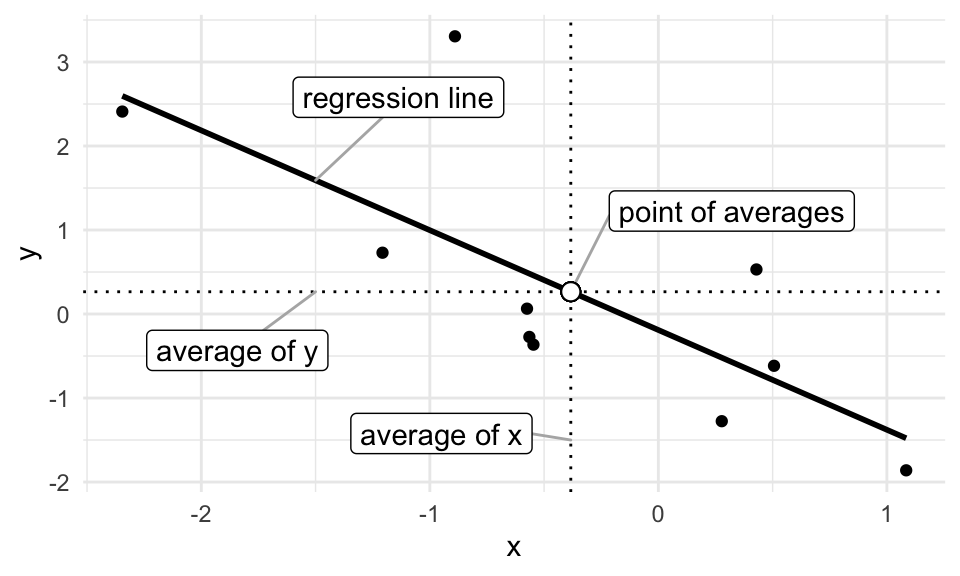
\[\begin{align} -2 \sum_{i = 1}^n(y_i - \hat{\alpha} - \hat{\beta} x_i) &= 0 \\ \sum_{i = 1}^n(y_i - \hat{\alpha} - \hat{\beta} x_i) &= 0 \text{ (divide both sizes by $-2$)} \\ \sum_{i = 1}^n y_i - \sum_{i = 1}^n \hat{\alpha} - \sum_{i = 1}^n \hat{\beta} x_i &= 0 \text{ (distribute the sum)} \\ \sum_{i = 1}^n y_i - n \hat{\alpha} - \hat{\beta}\sum_{i = 1}^n x_i &= 0 \text{ (move constant $\beta$ in front and realize that $\sum_{i = 1}^n \hat{\alpha} = n\hat{\alpha}$)} \\ \sum_{i = 1}^n y_i & = n \hat{\alpha} + \hat{\beta}\sum_{i = 1}^n x_i \text{ (rearrange)} \\ \frac{\sum_{i = 1}^n y_i}{n} & = \hat{\alpha} + \hat{\beta} \frac{\sum_{i = 1}^n x_i}{n} \text{ (divide both sides by $n$)} \\ \overline{y} & = \hat{\alpha} + \hat{\beta} \overline{x} \text{ (recognize the average of $y$ and of $x$)} \\ \end{align}\]
The figure below shows a regression line that goes through the point of averages.
10.4.3.1.2 The 2nd First-Order Condition
Sometimes, when writing proofs, you obtain a result that’s not particularly interesting, but true and useful later. We refer to these results as “lemmas.” We’ll need the following Lemmas in the subsequent steps.
A personal perspective on proofs: In my experience, proofs are not intuitive. Sometimes I have a sneaking suspicion about a result, but sometimes that sneaking suspicion is wildly wrong. When I investigate a the suspicion analytically, the path to the result is unclear. A maze analogy works quite well. To obtain the result, just move things around, sometimes getting further from the result. Eventually, you just happen upon the correct sequence of movements.
\[\begin{align} -2 \sum_{i = 1}^n(y_i - \hat{\alpha} - \hat{\beta} x_i)x_i &= 0 \\ \sum_{i = 1}^n(y_i - \hat{\alpha} - \hat{\beta} x_i)x_i &= 0 \text{ (divide both sides by -2)} \\ \sum_{i = 1}^n(y_i x_i - \hat{\alpha}x_i - \hat{\beta} x_i^2) &= 0 \text{ (distribute the $x_i$)} \end{align}\]
Now we can use use Theorem 10.2 and replace \(\hat{\alpha}\) with \(\overline{y} - \hat{\beta}\overline{x}\).
\[\begin{align} \sum_{i = 1}^n(y_i x_i - (\overline{y} - \hat{\beta}\overline{x})x_i - \hat{\beta} x_i^2) &= 0 \text{ (use the identity $\hat{\alpha} = \overline{y} - \hat{\beta}\overline{x}$)} \\ \sum_{i = 1}^n( x_i y_i - \overline{y} x_i + \hat{\beta}\overline{x} x_i - \hat{\beta} x_i^2) &= 0 \text{ (expand the middle term)} \\ \sum_{i = 1}^n x_i y_i - \overline{y} \sum_{i = 1}^n x_i + \hat{\beta}\overline{x} \sum_{i = 1}^n x_i - \hat{\beta} \sum_{i = 1}^n x_i^2 &= 0 \text{ (distribute the sum)} \end{align}\]
Now we can use Lemma 10.1 to replace \(\sum_{i = i}^n y_i\) with \(n\overline{y}\).
\[\begin{align} \sum_{i = 1}^n x_i y_i - n \overline{y} \overline{x} + \hat{\beta}n \overline{x}^2 - \hat{\beta} \sum_{i = 1}^n x_i^2 &= 0 \text{ (use the identity $\sum_{i = i}^n y_i = n\overline{y}$)}\\ \sum_{i = 1}^n x_i y_i - n \overline{x} \overline{y} &= \hat{\beta} \left(\sum_{i = 1}^n x_i^2 - n \overline{x}^2 \right) \text{ (rearrange)}\\ \hat{\beta} &=\dfrac{\sum_{i = 1}^n x_i y_i - n \overline{x} \overline{y}}{\sum_{i = 1}^n x_i^2 - n \overline{x}^2} \text{ (rearrange)}\\ \end{align}\]
This final result is correct, but unfamiliar. In order to make sense of this solution, we need to connect this identity to previous results.
Now we can use Lemmas 10.2 and 10.3 to replace the numerator \(\sum_{i = 1}^n x_i y_i - n \overline{x} \overline{y}\) with the more familiar expression \(\sum_{i = 1}^n (x_i - \overline{x})(y_i - \overline{y})\) and replace the denominator \(\sum_{i = 1}^n x_i ^2 - n \overline{x}^2\) with the more familiar expression \(\sum_{i = 1}^n (x_i - \overline{x})^2\).
\[\begin{align} \hat{\beta} &=\dfrac{\sum_{i = 1}^n (x_i - \overline{x})(y_i - \overline{y})}{\sum_{i = 1}^n (x_i - \overline{x})^2} \\ \end{align}\]
Denote the SD of \(x\) as \(\text{SD}_x\) and the the SD of \(y\) as \(\text{SD}_y\). Multiply the top and bottom by \(\frac{1}{n \times \text{SD}_x^2 \times \text{SD}_y}\) and rearrange strategically.
\[\begin{align} \hat{\beta} &=\frac{\frac{\sum_{i = 1}^n \left(\frac{x_i - \overline{x}}{\text{SD}_x} \right)\left(\frac{y_i - \overline{y}}{\text{SD}_y} \right)}{n} \times \frac{1}{\text{SD}_x}}{ \frac{1}{n \times \text{SD}_x^2 \times \text{SD}_y} \times \sum_{i = 1}^n (x_i - \overline{x})^2} \\ \end{align}\]
Now we recognize that the left term \(\dfrac{\sum_{i = 1}^n \left(\frac{x_i - \overline{x}}{\text{SD}_x} \right)\left(\frac{y_i - \overline{y}}{\text{SD}_y} \right)}{n}\) in the numerator is simply the correlation coefficient \(r\) between \(x\) and \(y\).
\[\begin{align} \hat{\beta} &=\dfrac{r \times \frac{1}{\text{SD}_x}}{\frac{1}{\text{SD}_x^2 \times \text{SD}_y}\sum_{i = 1}^n \frac{(x_i - \overline{x})^2}{n}} \\ \end{align}\]
Now we recognize that \(\sum_{i = 1}^n \frac{(x_i - \overline{x})^2}{n}\) is almost the \(\text{SD}_x\). Conveniently, it’s \(\text{SD}_x^2\), which allows us to cancel those two terms.
\[\begin{align} \hat{\beta} &=\dfrac{r \times \frac{1}{\text{SD}_x}}{\frac{1}{\text{SD}_y}} \\ & r \times \frac{\text{SD}_y}{\text{SD}_x} \end{align}\]
This final result clearly connects \(\hat{\beta}\) to previous results.
In summary, we can obtain the smallest RMS of the residuals with results from Theorems 10.2 and 10.3.
\[\begin{align} \hat{\beta} &= r \times \dfrac{\text{SD of } y}{\text{SD of }x} \\ \hat{\alpha} &= \overline{y} - \hat{\beta}\overline{x} \end{align}\]
Exercise 10.8 Other authors develop this least-squares approach using slightly different language and notation.
- Read FPP, ch. 12.
- Set A, p. 207: 1, 2, 3, 4.
- Set B, p. 210: 1, 2.
- Section 4, p. 213: 1-5, 8.
- Read Fox (2008), pp. 77-86. Do p. 96, q. 5.2.
- Read Wooldridge (2013), pp. 27-35. Do pp. 60-61, q. 3 (i, ii, and iii) and q. 6.
- Read DeGroot and Schervish (2012), pp. 689-692.
10.4.3.2 Matrix Form
In some cases, a matrix approach might help analytically or numerically compared to the scalar approach. Rather than writing the model as \(y_i = \alpha + \beta x_i + r_i\), we can write the model in an equivalent matrix form
\[\begin{align} y &= X\beta + r \\ \begin{bmatrix} y_1\\ y_2\\ \vdots\\ y_n \end{bmatrix} &= \begin{bmatrix} 1 & x_1\\ 1 & x_2 \\ \vdots & \vdots \\ 1 & x_n \end{bmatrix} \times \begin{bmatrix} \beta_1 \\ \beta_2\\ \end{bmatrix} + \begin{bmatrix} r_1\\ r_2\\ \vdots\\ r_n \end{bmatrix} . \end{align}\]
In this case, our intercept \(\alpha\) and slope \(\beta\) are combined into a single vector \(\beta = \begin{bmatrix} \beta_1 \\ \beta_2\\ \end{bmatrix}\), where \(\beta_1\) represents the intercept and \(\beta_2\) represents the slope.
Hint
Do the matrix multiplication \(X\beta\) and show that \(y_i = \beta_1 + \beta_2x + r_i\).Proof
See Fox (2008), pp. 192-19310.5 The RMS of the Residuals
Just like the SD offers a give-or-take number around the average, the RMS of the residuals offers a give-or-take number around the regression line.
Indeed, the SD is the RMS of the deviations from the average and the RMS of the residuals is the RMS of the deviations from the regression line. The RMS of the residuals tells us how far typical points fall from the regression line.
Sometimes the RMS of the residuals is called the “RMS error (of the regression),” the “standard error of the regression,” or denoted as \(\hat{\sigma}\).
We can compute the RMS of the regression by computing each residual and then taking the root-mean-square. But we can also use the much simpler formula \(\sqrt{1 - r^2} \times \text{ SD of }y\).
This formula makes sense because \(y\) has an SD, but \(x\) explains some of that variation. As \(r\) increases, \(x\) explains more and more of the variation. As \(x\) explains more variation, then the RMS of the residuals shrinks away from SD of \(y\) toward zero. It turns out that the SD of \(y\) shrinks toward zero by a factor of \(\sqrt{1 - r^2}\).
Exercise 10.11 Read FPP, ch. 11. Do the following exercises.
- Set A, p. 184: 1-4, 6, 7.
- Set B, p. 187: 1, 2.
- Set C, p. 189: 1-3.
- Set D, p. 193: 1, 2, 4-6.
- Set E, p. 197: 1, 2.
- Section 6, p. 198: 1, 2, 4, 6, 7,10, 12.
10.6 \(R^2\)
Some authors use the quantity \(R^2\) to assess the fit of the regression model. I prefer the RMS of the residuals because it’s on the same scale as \(y\). Also, \(R^2\) computes the what fraction of the variance of \(y\), which is the SD squared, is explained by \(x\). I have a hard time making sense of variances, because they are not on the original scale.
However, \(R^2\) is a common quantity, so do the following exercises.
10.6.1 Adequacy of a Line
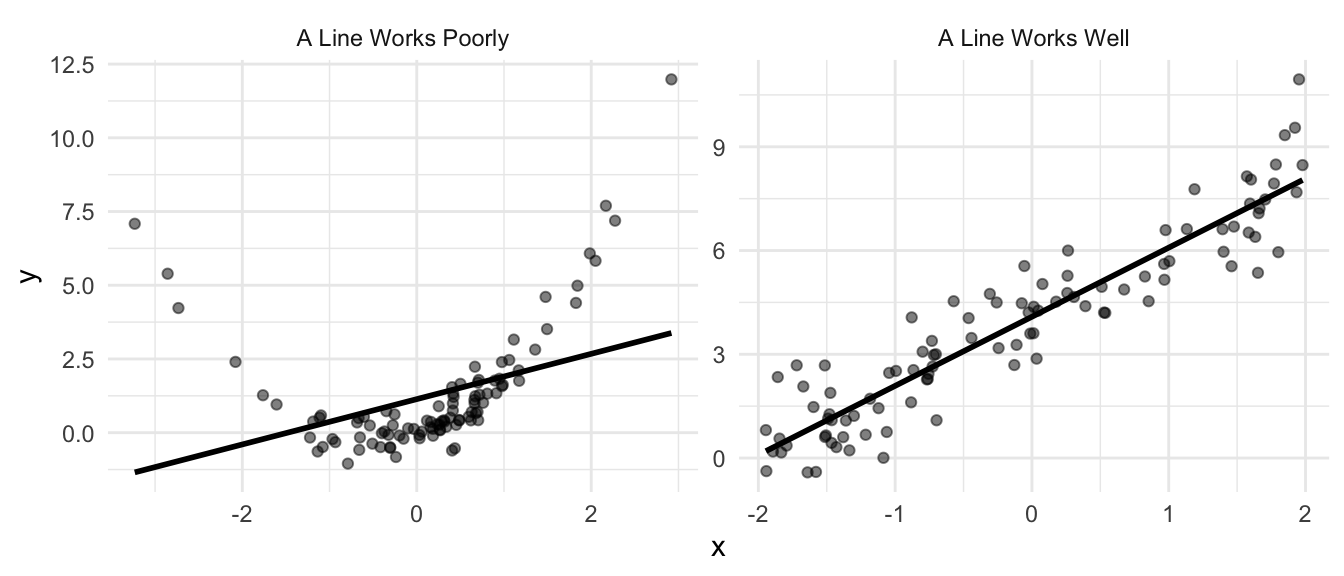
In some cases, a line can describe the average value \(y\) quite well. In other cases, a line describes the data poorly.
Remember, the regression line describes the average value of \(y\) for different values of \(x\). In the figure below, the left panel shows a dataset in which a line does not (and cannot) adequately describe the average values of \(y\) for describe low, middle, and high values (at least ad the same time). The right panel shows a data in which a line can adequately describe how the average value of \(y\) changes with \(x\). We can see that when \(x \approx -2\), then \(y \approx 0\). Similarly, when \(x \approx 0\), then \(y \approx 4\). A line can describe the average value of \(y\) for varying values of \(x\) when the average of \(y\) changes linearly with \(x\).
A line does a great job of describing the relationship between seat shares and portfolio shares in government coalitions.
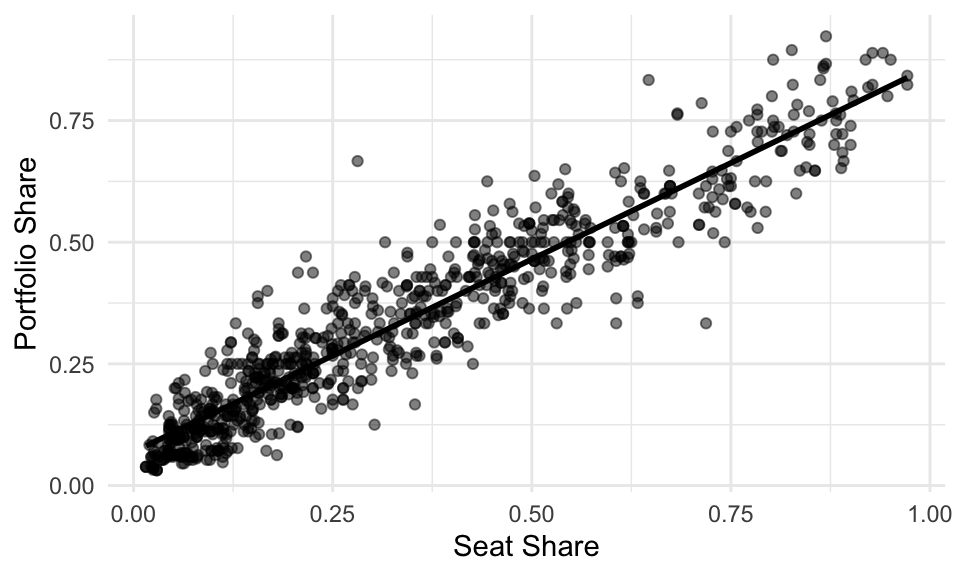
A line poorly describes the relationship between Polity IV’s DEMOC measure and GDP per capita.
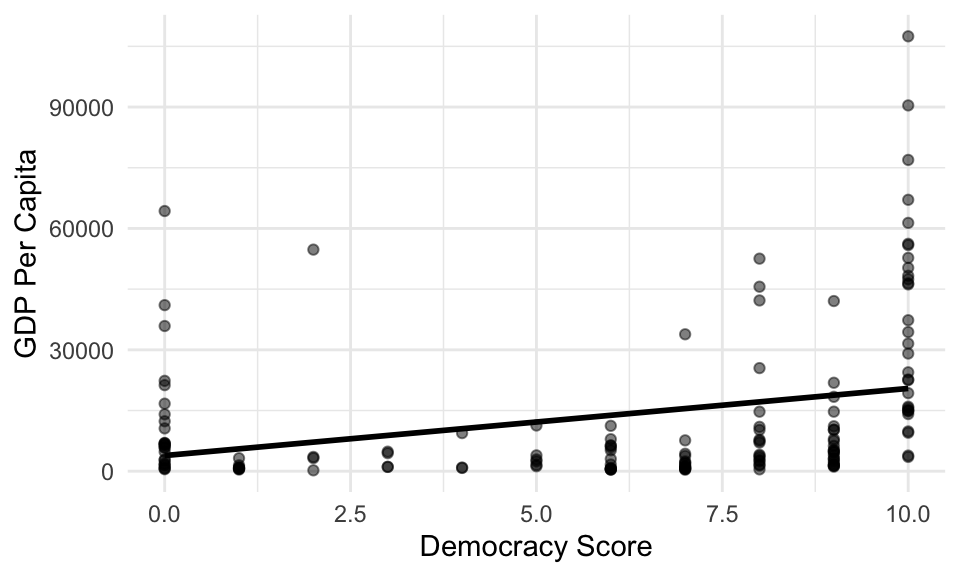
When we have variable that’s skewed heavily to the right, we can sometimes more easily describe the log of the variable. For this dataset, the line poorly describes the average logged GDP per capita for the various democracy scores.
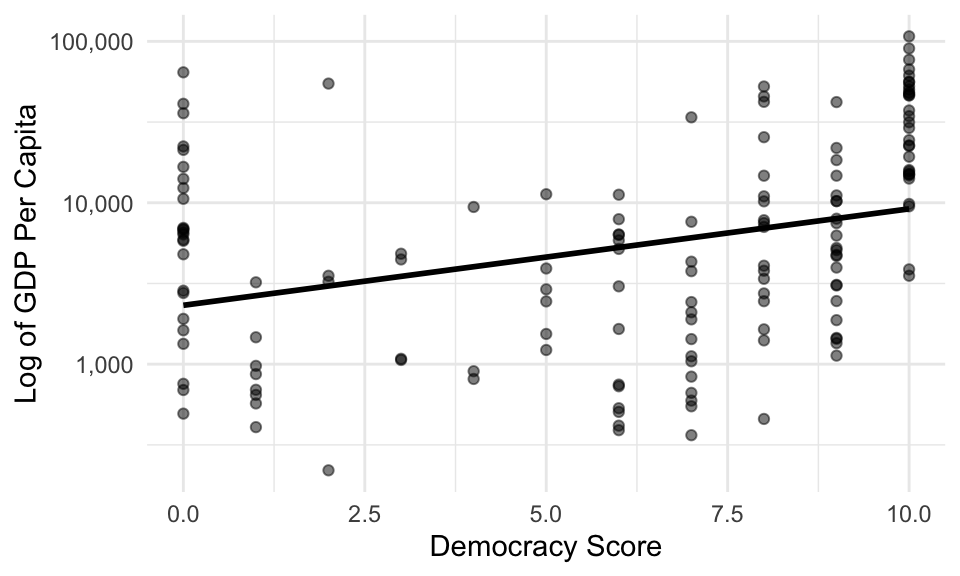
10.7 Fitting Regression Models
To fit a regression model in R, we can use the following approach:
- Use
lm()to fit the model. - Use
coef(),arm::display(),texreg::screenreg(), orsummary()to quickly inspect the slope and intercept. - Use
glance(),tidy(), andaugment()functions in the broom package to process the fit more thoroughly.
10.7.1 geom_smooth()
In the context of ggplot, we can show the fitted line with geom_smooth().
gamson <- read_rds("data/gamson.rds")
ggplot(gamson, aes(x = seat_share, y = portfolio_share)) +
geom_point() +
geom_smooth()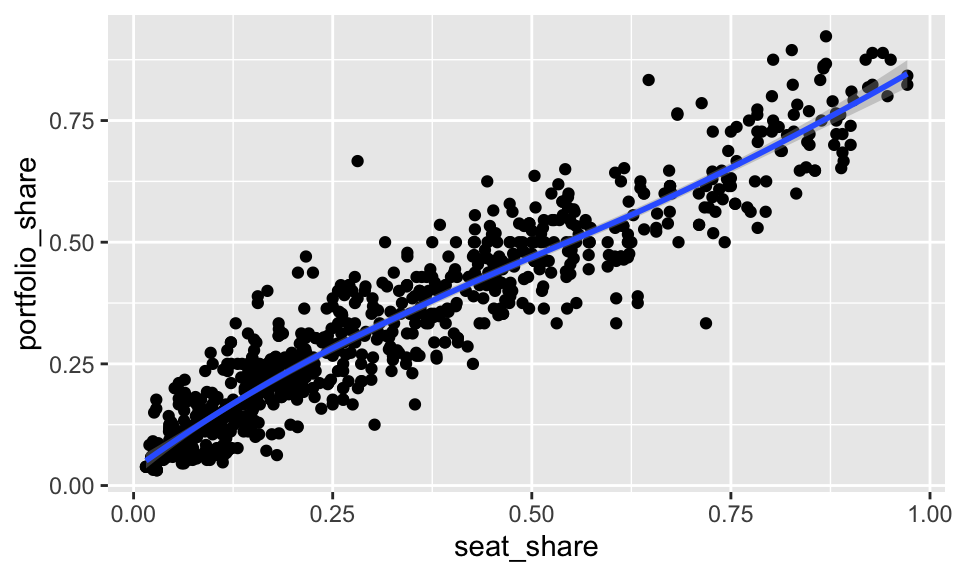
By default, geom_smooth() fits a smoothed curve rather than a straight line. There’s nothing wrong with a smoothed curve—sometimes it’s preferable to a straight line. But we don’t understand how to fit a smoothed curve. To us the least-squares fit, we supply the argument method = "lm" to geom_smooth().
geom_smooth() also includes the uncertainty around the line by default. Notice the grey band around the line, especially in the top-right. We don’t have a clear since of how uncertainty enters the fit, nor do we understand a standard error, so we should not include the uncertainty in the plot (at least for now). To remove the grey band, we supply the argument se = FALSE to geom_smooth().
The line \(y = x\) is theoretically relevant–that’s the line that indicates a perfectly proportional portfolio distribution. To include it, we can use geom_abline().
ggplot(gamson, aes(x = seat_share, y = portfolio_share)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
geom_abline(intercept = 0, slope = 1, color = "red")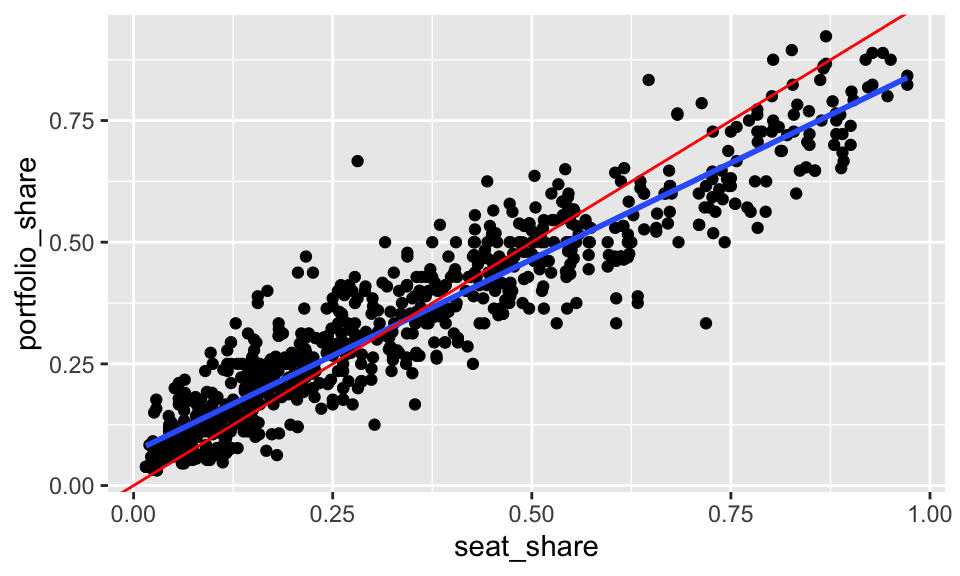
10.7.2 lm()
The lm() function takes two key arguments.
- The first argument is a formula, which is a special type of object in R. It has a left-hand side and a right-hand side, separated by a
~. You put the name of the outcome variable \(y\) on the LHS and the name of the explanatory variable \(x\) on the RHS. - The second argument is the dataset.
10.7.3 Quick Look at the Fit
We have several ways to look at the fit. Experiment with coef(), arm::display(), texreg::screenreg(), and summary() to see the differences. For now, we only understand the slope and intercept, so coef() works perfectly.
(Intercept) seat_share
0.06913558 0.79158398 The coef() function outputs a numeric vector with named entries. The intercept is named (Intercept) and the slope is named after its associated variable.
10.7.4 Post-Processing
The intercept and slope have a nice, intuitive interpretation so it’s tempting to just examine those values and call it quits. That’s a mistake, and it’s an especially bad habit to carry into richer models.
The broom package offers three useful tools to explore the fit in more detail. The core of broom contains three functions: glance(), tidy(), and augment(). broom works nicely in our usual workflow because it produces a data frame containing information about the fit. These functions work for a wide range of models, so you can use this workflow as models become richer.
10.7.4.1 glance()
glance() produces a one-row data frame that contains summaries of the model fit.
Rows: 1
Columns: 12
$ r.squared <dbl> 0.8879625
$ adj.r.squared <dbl> 0.8878265
$ sigma <dbl> 0.06889308
$ statistic <dbl> 6530.681
$ p.value <dbl> 0
$ df <dbl> 1
$ logLik <dbl> 1038.673
$ AIC <dbl> -2071.346
$ BIC <dbl> -2057.196
$ deviance <dbl> 3.910916
$ df.residual <int> 824
$ nobs <int> 826We don’t understand many of these (yet, see ?glance.lm for the definitions), so let’s select() only those we understand.
fit_summary <- glance(fit) %>%
select(r.squared, sigma) %>% # this used to have nobs, but not any more
glimpse()Rows: 1
Columns: 2
$ r.squared <dbl> 0.8879625
$ sigma <dbl> 0.06889308r.squaredis the \(R^2\) statistic.sigmais the RMS of the residuals.nobsis the number of observations (see note above).
10.7.4.2 tidy()
tidy() produces a usually several-row data frame that contains summaries of the “components” of the model. The “components” are usually the main focus of the model. In the case of an lm() fit, it’s the intercept and slope(s).
Rows: 2
Columns: 5
$ term <chr> "(Intercept)", "seat_share"
$ estimate <dbl> 0.06913558, 0.79158398
$ std.error <dbl> 0.004037815, 0.009795300
$ statistic <dbl> 17.12203, 80.81263
$ p.value <dbl> 1.865252e-56, 0.000000e+00You can see that tidy gives us one row per coefficient (one for intercept and one for slope).
Again, there are several columns we don’t understand (yet, see ?tidy.lm for the definitions), so let’s select() the rows we know.
Rows: 2
Columns: 2
$ term <chr> "(Intercept)", "seat_share"
$ estimate <dbl> 0.06913558, 0.79158398termcontains the name of the coefficient.estimatecontains the estimate for that coefficient.
This gives us the same information as coef(fit), except in a data frame rather than a named vector. The data frame is more convenient for computing and plotting. For example, we can plot the coefficients.
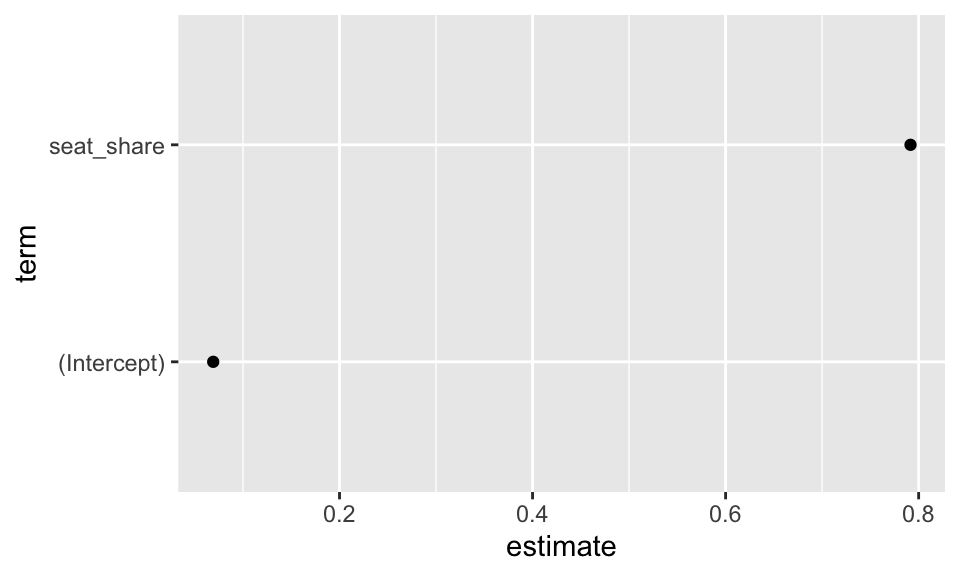
You can see that this sort of plot might be useful for more complicated models. We might have similar models that we want to compare, or the same model fit to different subsets of data.
10.7.4.3 augment()
Lastly, augment() creates a data frame with information about each observation.
Rows: 826
Columns: 8
$ portfolio_share <dbl> 0.09090909, 0.36363637, 0.54545456, 0.45454547, 0.545…
$ seat_share <dbl> 0.02424242, 0.46060607, 0.51515150, 0.47204968, 0.527…
$ .fitted <dbl> 0.0883255, 0.4337440, 0.4769213, 0.4428026, 0.4870526…
$ .resid <dbl> 0.002583595, -0.070107594, 0.068533303, 0.011742918, …
$ .std.resid <dbl> 0.03756019, -1.01841671, 0.99571954, 0.17058860, 0.84…
$ .hat <dbl> 0.003121865, 0.001546470, 0.001890853, 0.001608751, 0…
$ .sigma <dbl> 0.06893487, 0.06889153, 0.06889344, 0.06893371, 0.068…
$ .cooksd <dbl> 2.209010e-06, 8.032205e-04, 9.391259e-04, 2.344542e-0…Again, there are several columns we don’t understand (yet, see ?augment.lm for the definitions), so let’s select() the rows we know.
Rows: 826
Columns: 4
$ portfolio_share <dbl> 0.09090909, 0.36363637, 0.54545456, 0.45454547, 0.545…
$ seat_share <dbl> 0.02424242, 0.46060607, 0.51515150, 0.47204968, 0.527…
$ .fitted <dbl> 0.0883255, 0.4337440, 0.4769213, 0.4428026, 0.4870526…
$ .resid <dbl> 0.002583595, -0.070107594, 0.068533303, 0.011742918, …- The couple of variables are the \(x\) and \(y\) from the original dataset used to fit the model.
.fittedis the fitted or predicted value that we denote as \(\hat{y}\).residis the residual or the difference between the predicted and observed value.
Now we have an important data set for assessing the fit of the model. Does it describe the data well? Poorly? We can use augment()ed dataset to create a plot of the fitted/predicted values versus the residuals.
ggplot(obs_fit, aes(x = .fitted, y = .resid)) +
geom_point() +
geom_hline(yintercept = 0, color = "red")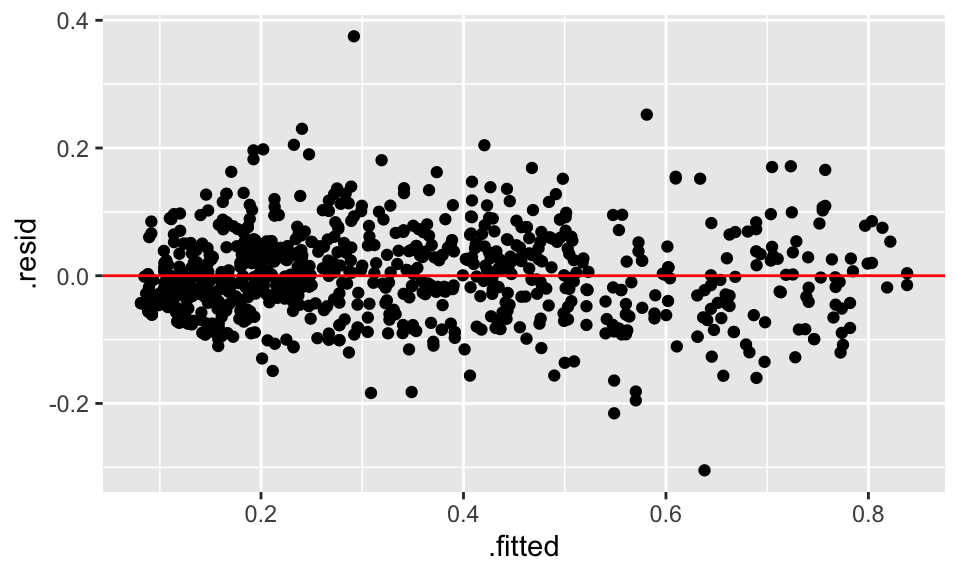
glance(), tidy(), and augment() to obtain data frames with the information of the fit. Create a fitted versus residual plot and use to to make a judgement about the fit of the model to the data. Review FPP, pp. 187-192 for more about plotting the fitted values verus the residuals.
Solution
dem_life <- read_csv("https://raw.githubusercontent.com/pos5737/democracy-life/master/data/democracy-life.csv") %>%
glimpse()Rows: 151
Columns: 8
$ year <dbl> 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016,…
$ country_name <chr> "United States", "Canada", "Cuba", "Dominican Republi…
$ wb <chr> "USA", "CAN", "CUB", "DOM", "JAM", "TTO", "MEX", "GTM…
$ cown <dbl> 2, 20, 40, 42, 51, 52, 70, 90, 91, 92, 93, 94, 95, 10…
$ life_expectancy <dbl> 78.53902, 82.14224, 78.60700, 73.47100, 74.17500, 73.…
$ gdp_per_capita <dbl> 52534.365, 50263.834, 6550.274, 7084.627, 4753.705, 1…
$ democ <dbl> 8, 10, 0, 8, 9, 10, 8, 9, 7, 8, 7, 10, 9, 7, 8, 6, 6,…
$ autoc <dbl> 0, 0, 7, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0,…# A tibble: 1 x 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.0946 0.0886 18826. 15.6 1.22e-4 1 -1700. 3405. 3414.
# … with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int># A tibble: 2 x 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3869. 2984. 1.30 0.197
2 democ 1659. 420. 3.95 0.000122Rows: 151
Columns: 8
$ gdp_per_capita <dbl> 52534.365, 50263.834, 6550.274, 7084.627, 4753.705, 15…
$ democ <dbl> 8, 10, 0, 8, 9, 10, 8, 9, 7, 8, 7, 10, 9, 7, 8, 6, 6, …
$ .fitted <dbl> 17138.532, 20455.803, 3869.446, 17138.532, 18797.167, …
$ .resid <dbl> 35395.834, 29808.031, 2680.829, -10053.905, -14043.462…
$ .std.resid <dbl> 1.8881716, 1.5947603, 0.1442260, -0.5363201, -0.750048…
$ .hat <dbl> 0.008435309, 0.014230460, 0.025121117, 0.008435309, 0.…
$ .sigma <dbl> 18661.80, 18727.25, 18887.83, 18870.91, 18853.46, 1888…
$ .cooksd <dbl> 0.0151646668, 0.0183571132, 0.0002680066, 0.0012234835…ggplot(obs_df, aes(x = .fitted, y = .resid)) +
geom_point() +
geom_hline(yintercept = 0, color = "red")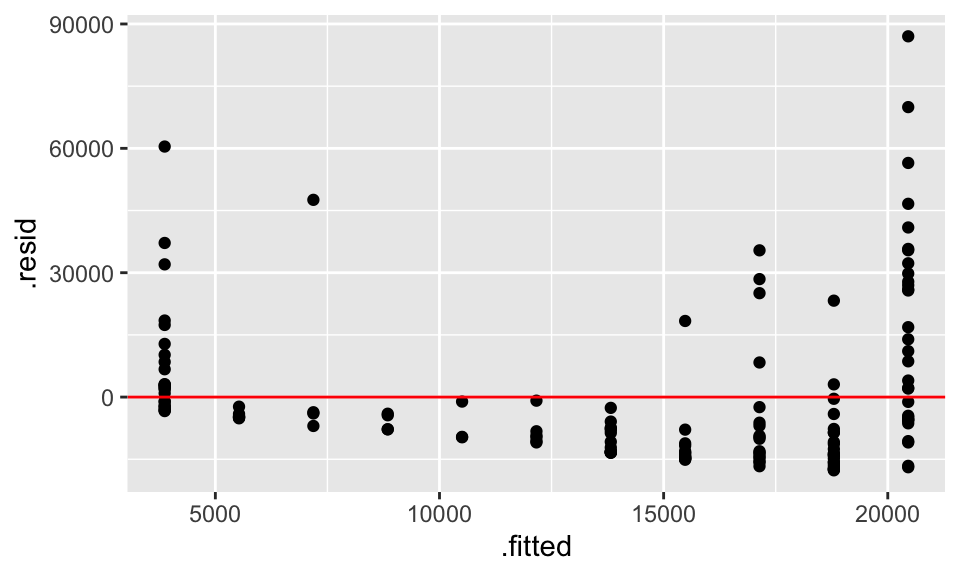
10.8 Standard Errors and p-Values
Almost all software reports p-values or standard errors by default. At this point, you should ignore these. In order to use these, you must be able to:
- Define a p-value. It’s the probability of…?
- Define a sampling distribution.
- Describe how randomness noise makes it’s way into your fitted coefficients.
We’ll take a lot of care with (1) and (2). For most applications, it isn’t at all immediately clear how randomness enters the data (if at all).
That said, regression is a powerful tool for description. Use it often.
10.9 A Warning
When we simply describe a single set of measurements with a histogram or an average, then we intuitively remain in the world of description. Indeed, making a causal claim requires a comparing factual and counterfactual scenarios. In the case of a single histogram or average we only have one scenario and there is no comparison.
When we have descriptions of multiple sets of measurements, say the average life expectancy for democracies and the average life expectancy for autocracies, we an easily interpret one scenario as factual and the other as counterfactual. On its face, though, both scenarios are factual. We can comfortably say that democracies have healthier populations than autocracies without claiming that the regime type causes this difference. But it is… oh. so. tempting.
Regression models, by design, describe an outcome across a range of scenarios. Indeed, a regression model describes how the average value of \(y\) changes as \(x\) varies. The temptation to treat these neatly arranged scenarios as factual and counterfactual grows even stronger. But unless one makes a strong argument otherwise, statistical models describe the factual world.
With few exceptions, statistical data analysis describes the outcomes of real social processes and not the processes themselves. It is therefore important to attend to the descriptive accuracy of statistical models, and to refrain from reifying them. —Fox (2008, p.3)
Note that some methodologists claim that their statistical models can obtain estimates of the causal effects. These models might actually succeed on occasion. However, the researcher should carefully avoid seeing counterfactual worlds from regression models. Usually, credible causal inferences come from careful design in the data collection stage, not from complicated conditioning at the modeling stage.
10.10 Review Exercises
Exercise 10.15 Use devtools::install_github("pos5737/pos5737data") to get the latest version of the pos5737 data package. Load the data set anscombe into R with data(anscombe, package = "pos5737data"). Use glimpse(anscombe) to get a quick look at the data. Realize that this one data frame actually contains four different datasets stacked on top of each other and numbered I, II, III, and IV.
- Fit a regression model on each “dataset” in the anscombe dataset. To only use a subset of the dataset, you can
filter()the dataset before supplying thedatatolm()or use can supply thesubsetargument tolm(). In this case, just supplyingsubset = dataset == "I", for example, is probably easiest. Fit the regression to all four datasets and put the intercept, slope, RMS of the residuals, and number of observations for each regression in a little table. Interpret the results. - For each of the four regression fits, create a scatterplot of the fitted values versus the residuals. Describe any inadequacies.
Exercise 10.17 Use a regression model (fit in R) to assess the question in Exercise 10.1. Briefly discuss the strengths and weaknesses of each approach.
- Histogram
- Average and/or SD
- Scatterplot
- Correlation Coefficient
- Regression
Exercise 10.18 This continues Exercise 10.1. Get the economic-model CSV dataset from GitHub.
- In three separate regressions, use GDP, RDI, and unemployment to explain the incumbent’s margin of victory. Which measure of economic performance best describes incumbents’ vote shares?
- Using the best model of the three, which incumbents did much better than the model suggests? Which incumbents did much worse?